Introduction
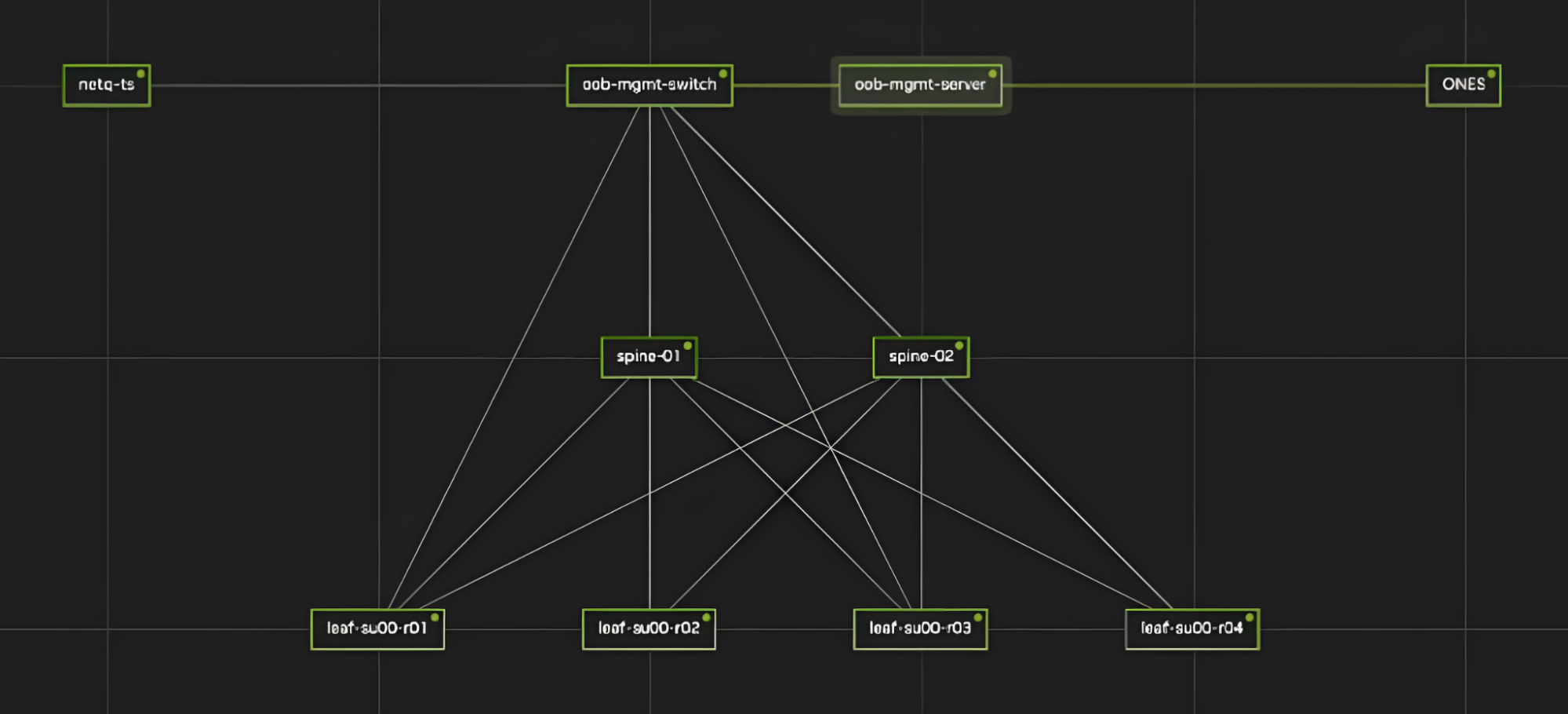
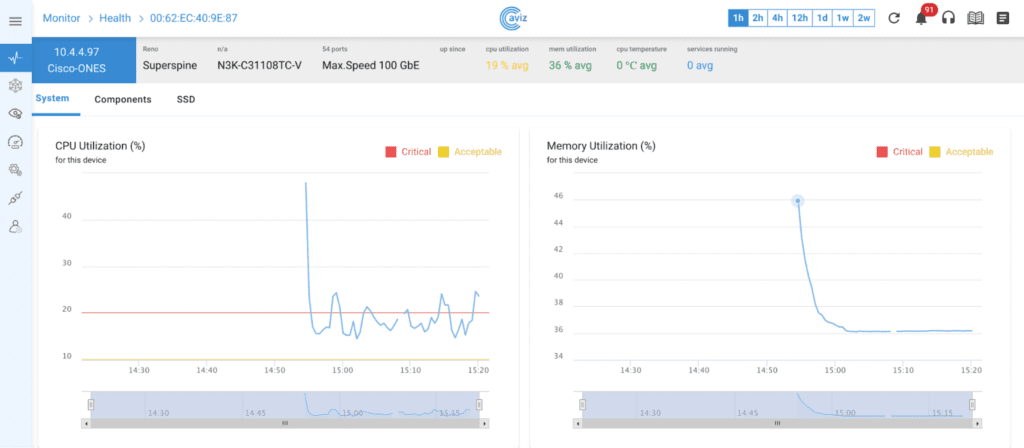
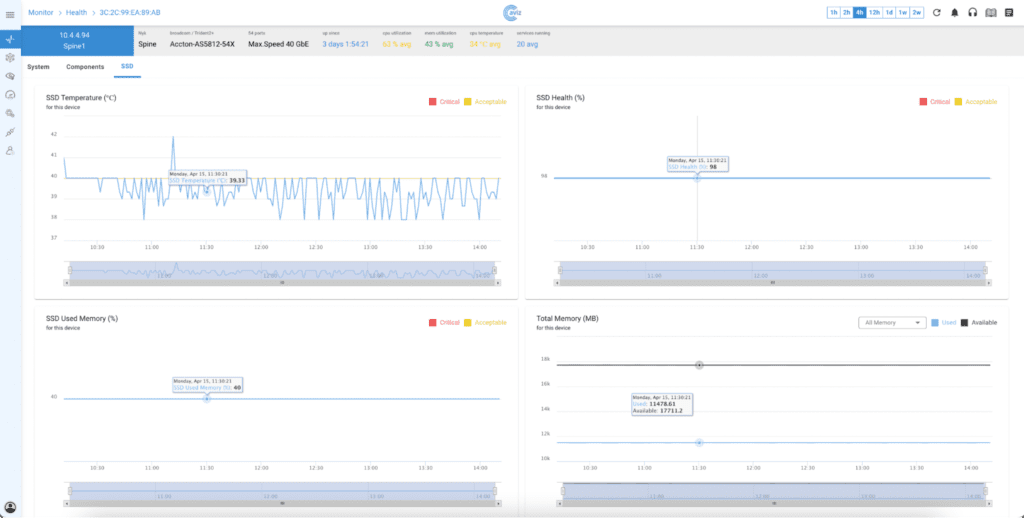
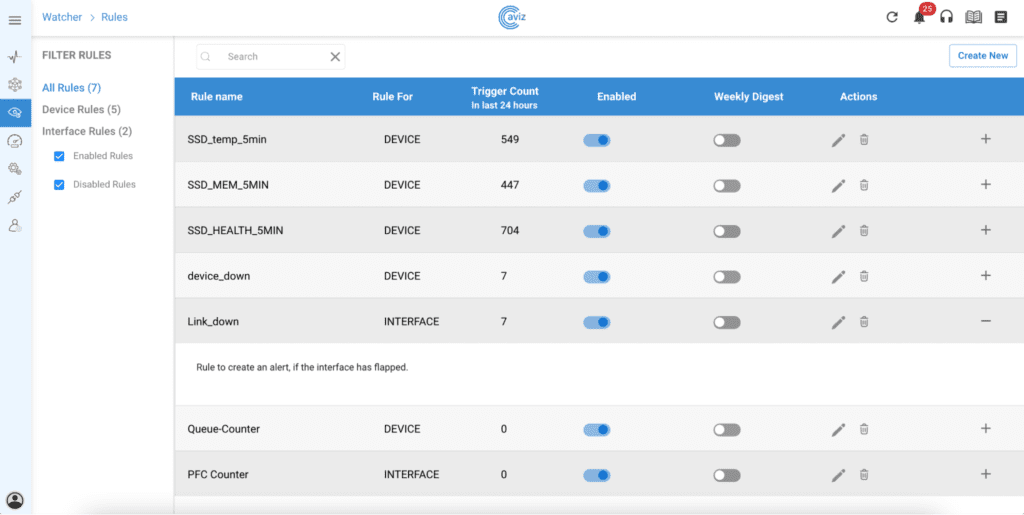
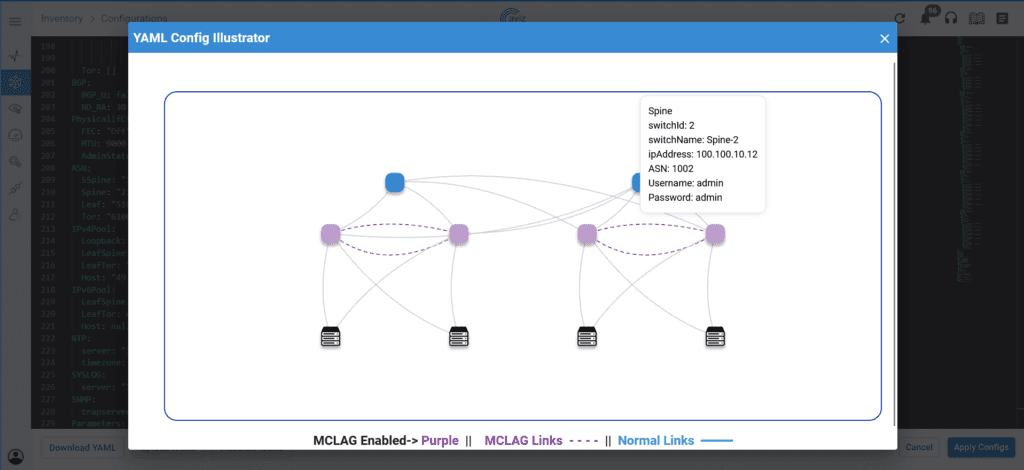
In today’s digital era, network efficiency plays a pivotal role in determining the quality of communication and data exchange. Whether for data centers, service providers, or end-users, understanding key network Key Performance Indicators(KPI) like latency and bandwidth is crucial. These KPIs directly influence application performance, video streaming quality, online gaming, and cloud-based services. The ability to measure and optimize these parameters ensures a seamless user experience and improved network reliability. Lets discuss in detail on how Aviz Service Node (ASN) efficiently computes the different KPIs of any Network (Telco, DC, Edge, FTTH, Campus) and helps in achieving the refined Network Observability in this blog.
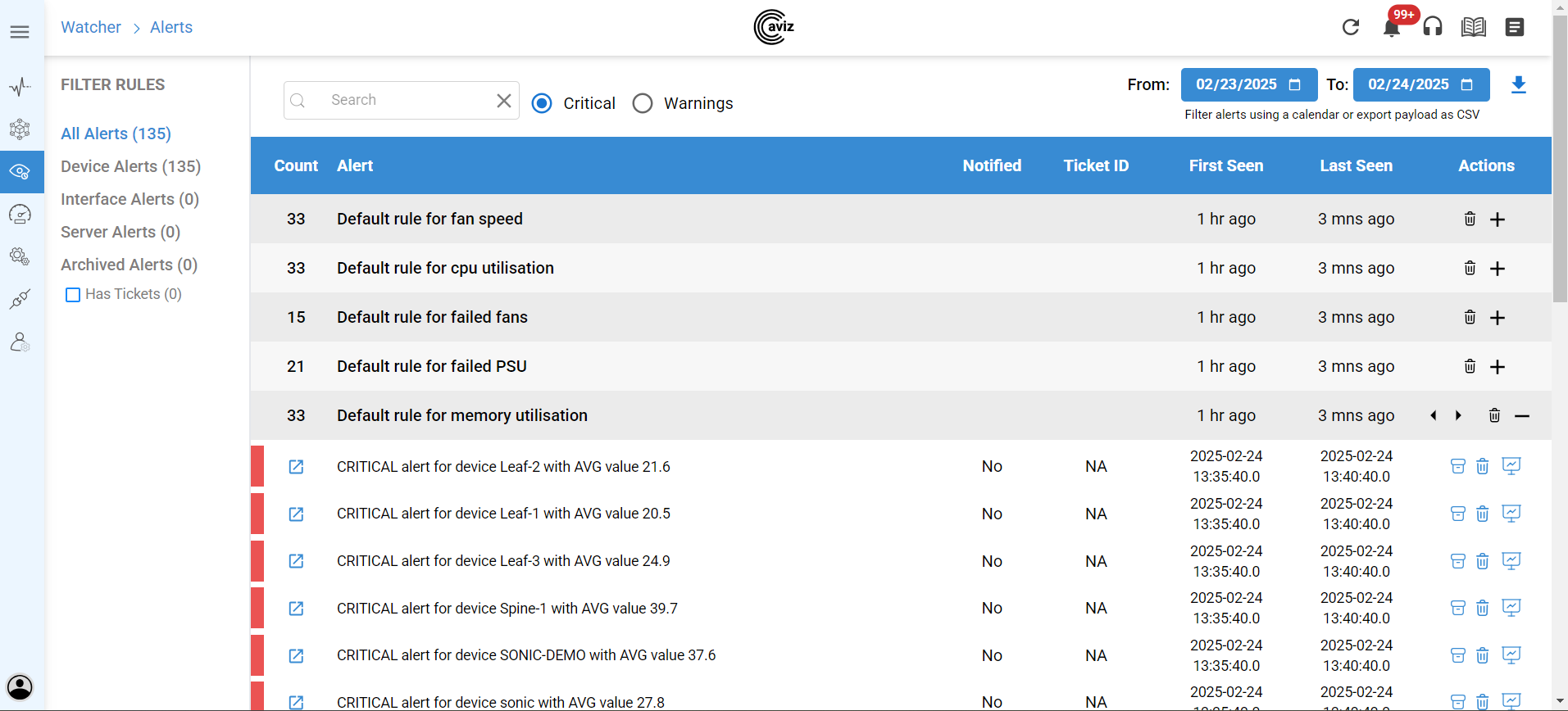
Supported KPIs
- Session based Packet Stats: ASN keeps track of the sessions and calculates the Total number of packets, Total Bytes for each session processed in the ASN. The stats are processed for each session direction - Uplink and Downlink.
- Latency: Latency is the time it takes for a packet of data to travel from the User equipment(UE) to the Data Network(DN) and back. ASN measures the latency with the accuracy in nanoseconds (ns) and can be affected by factors such as network congestion, distance, processing, Queuing and Transmission delays. High latency results in lag, negatively impacting real-time applications like video conferencing, Gaming, VoIP etc.,
- Bandwidth: Bandwidth is the maximum data transfer rate of a network, measured in Bytes per second (Bps). It determines how much data can be sent or received within a given timeframe. High bandwidth enables faster data transfer, reducing buffering and improving performance for high-demand applications. The major factors affecting Bandwidth are Network infrastructure, capacity, congestion, overheads.
- TimeStamps: ASN can calculate bandwidth and latency based on Network timestamps if present in the packet. But ASN also can add the timestamp to the packet at nanosecond accuracy which will help in calculating the interval based KPIs.
KPI Calculation
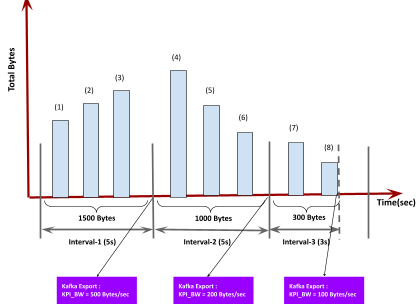
ASN calculates average bandwidth and latency at 5-second intervals and exports the KPI data to a Kafka topic. Additionally, when a session is closed before the completion of the 5-second interval, the system triggers an export to a priority Kafka topic. This ensures real-time observability and accurate metric reporting.
- Bandwidth is computed as the total bytes transmitted every second and average of the 5-second window as well.
- If a session terminates early, the actual bandwidth data (for the shorter duration) is calculated and exported immediately to a priority Kafka topic.
- The system ensures precise tracking by timestamping every exported KPI event.
This guarantees that critical network metrics are available in real time, allowing for improved monitoring, anomaly detection, and performance optimization.

KPIs Supported Matrix
| KPIS | Per Session | Per Application | Per Region |
|---|---|---|---|
| Throughput/Bandwidth | |||
| Uplink Latency | |||
| Downlink Latency | |||
| Retransmit count | |||
| Total Packets and Bytes |
Key Benefits of Optimizing Latency and Bandwidth
- Enhanced User Experience: Reduced latency ensures smoother online interactions, while higher bandwidth prevents buffering and slowdowns.
- Improved Real-Time Communication: Low-latency networks are crucial for VoIP, gaming, and financial transactions.
- Better Cloud Service Performance: Optimized bandwidth supports seamless cloud storage and computing.
- Scalability and Reliability: Networks with high bandwidth and low latency can handle increased traffic efficiently.
- Increased Productivity: Faster and more reliable networks enhance workplace efficiency by reducing downtime.
Conclusion
Network KPIs are fundamental for evaluating and improving network performance. As businesses and consumers rely more on digital services, optimizing these metrics becomes imperative for delivering seamless connectivity. By leveraging advanced network observability strategies of ASN, Networks can enhance user experience, reduce delays, and ensure robust performance. Monitoring and optimizing latency and bandwidth will continue to be essential in the evolution of next-generation networking technologies.