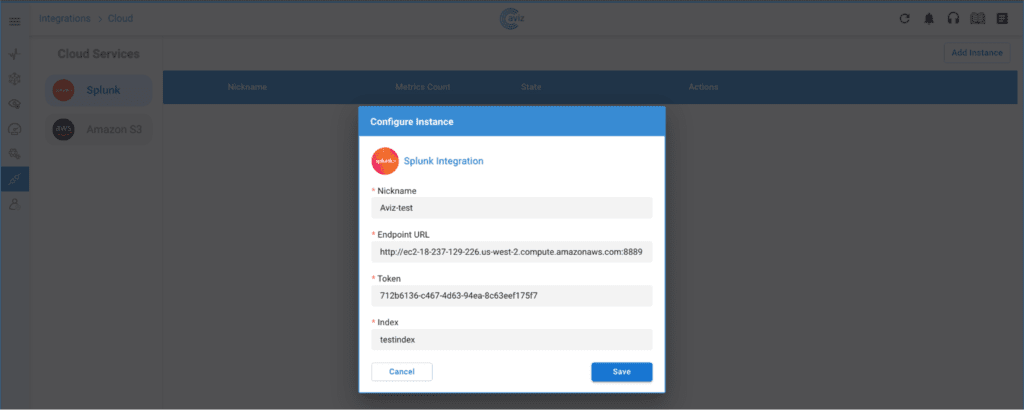
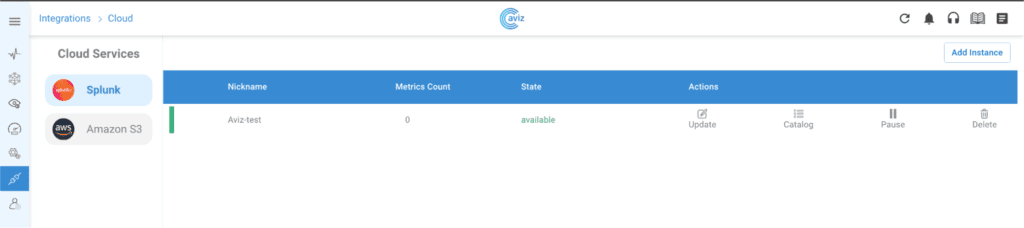
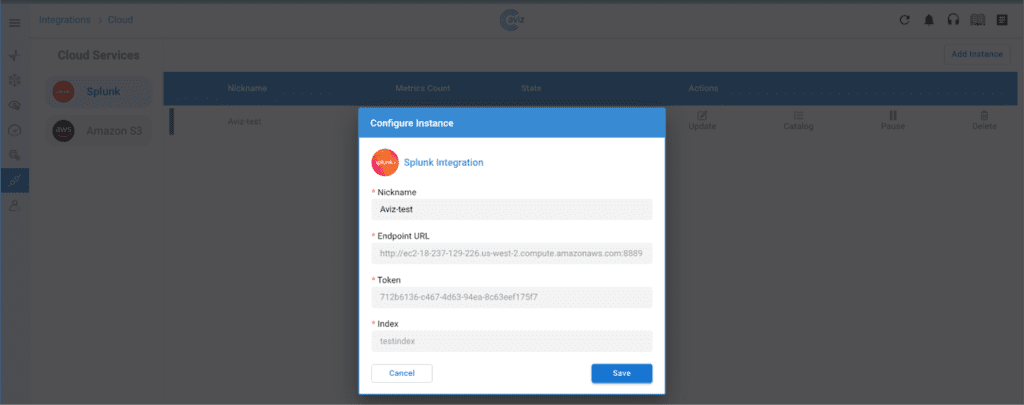
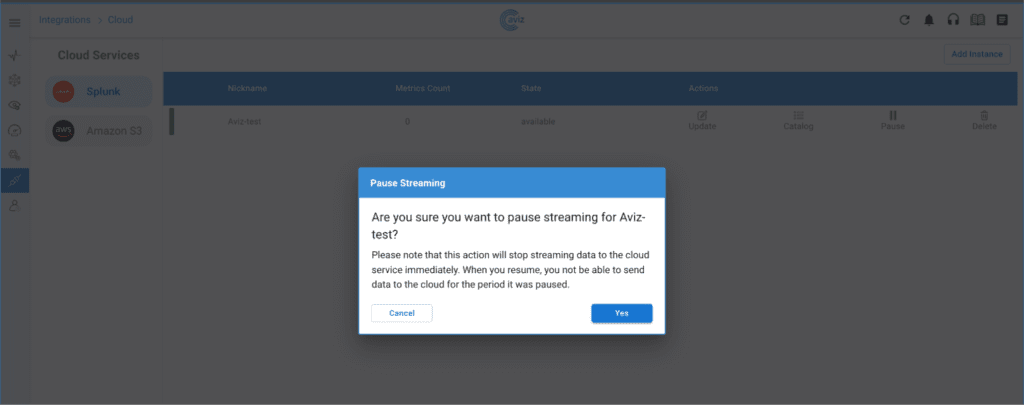
AI is transforming every industry—including networking. As AI workloads scale, the infrastructure powering them must evolve. Networks must become smarter, faster, and more efficient to support the next wave of AI-driven innovation. At Aviz Networks, we believe in Networks for AI and AI for Networks—and we’re making it happen.
That’s why I’m thrilled to invite you to an exclusive panel at NVIDIA GTC, where we’ll explore NVIDIA’s role in transforming networking across these two dimensions and how Aviz Networks complements this ecosystem with innovative products.
Panel: Network Modernization in the Age of AI
AI-driven workloads demand a new era of networking—one that redefines how we design, deploy, and optimize infrastructure for peak performance. Our discussion will cover:
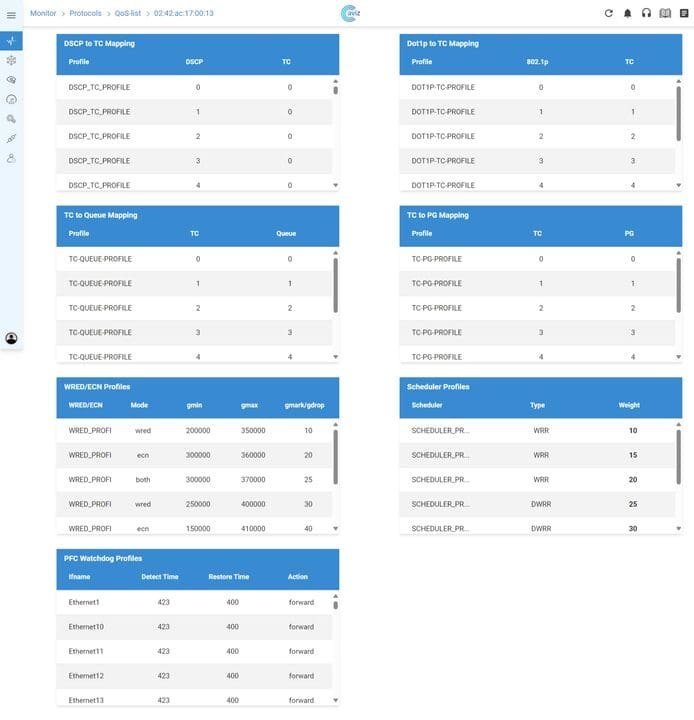
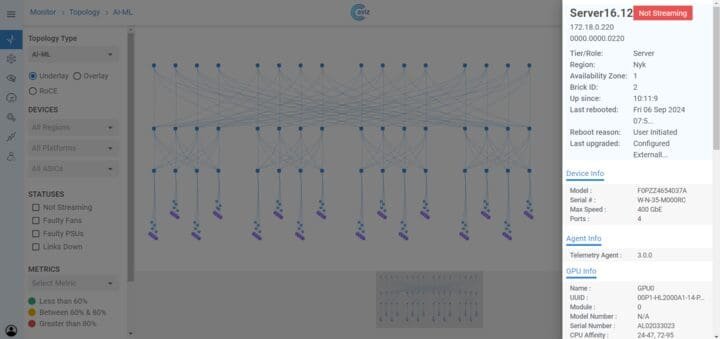
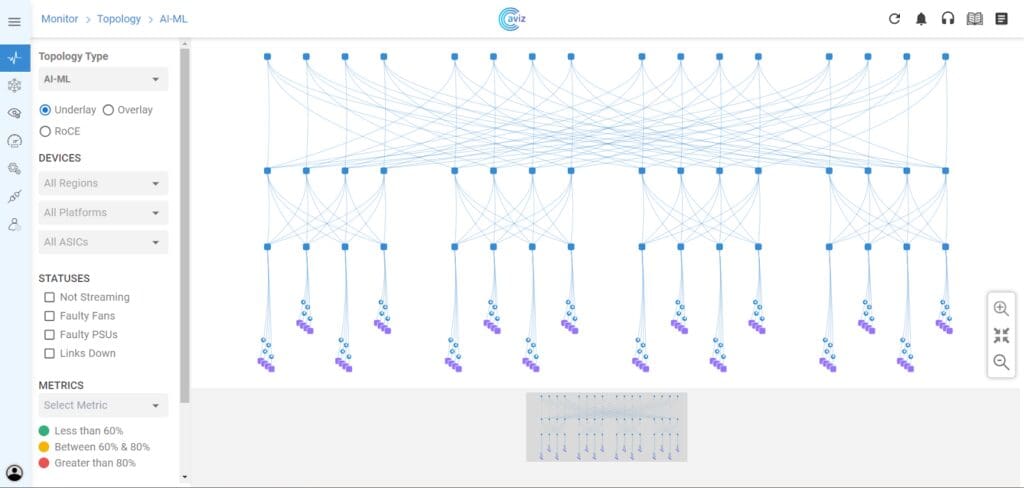
- Networks for AI – Discover cutting-edge architectures designed to deliver high-performance, lossless networking for AI workloads
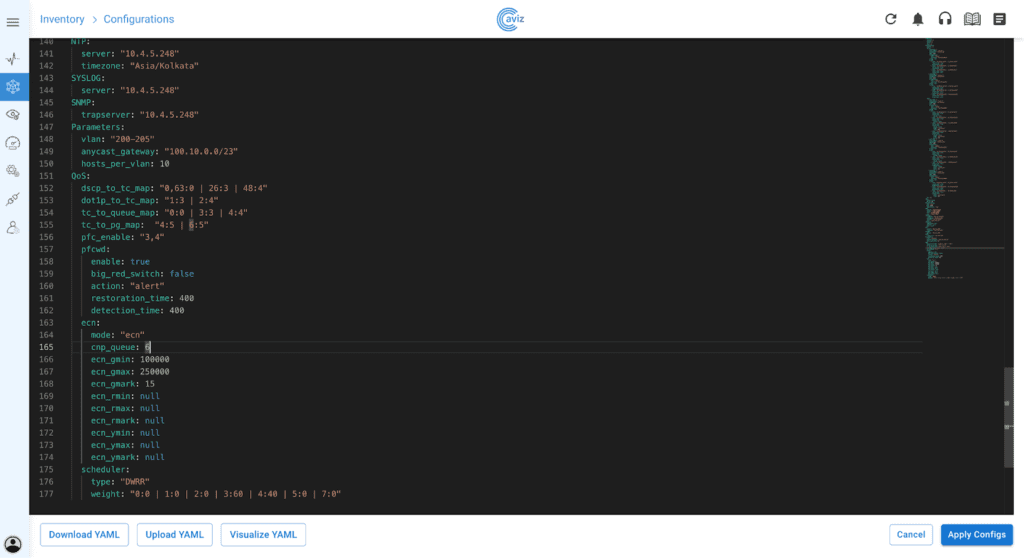
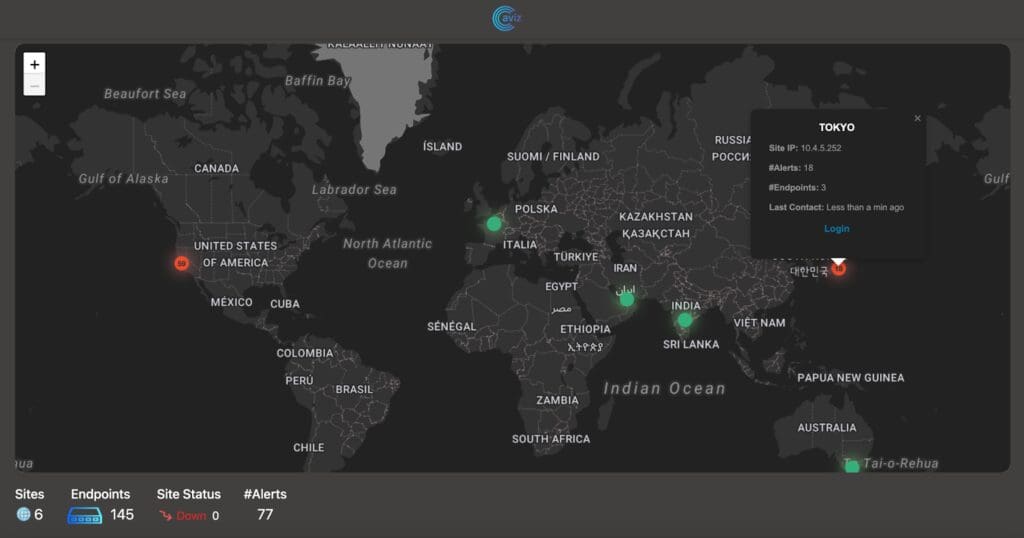
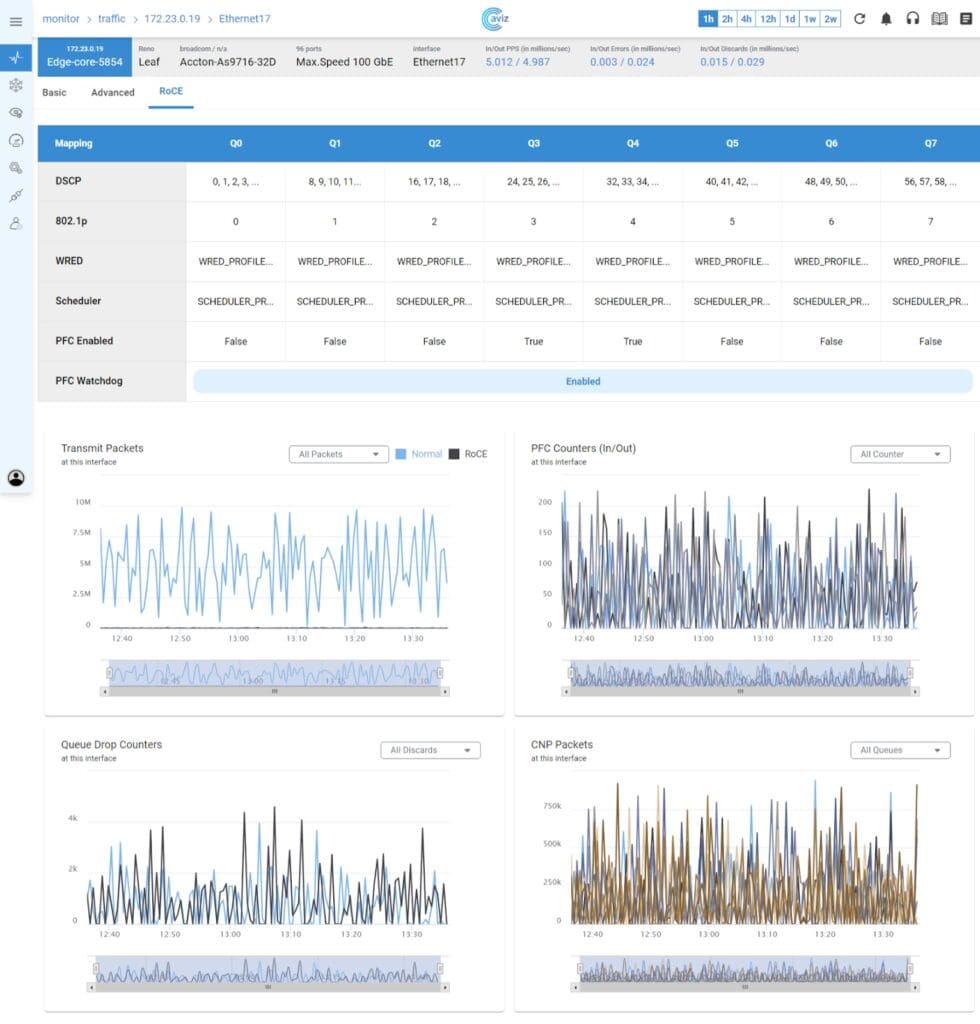
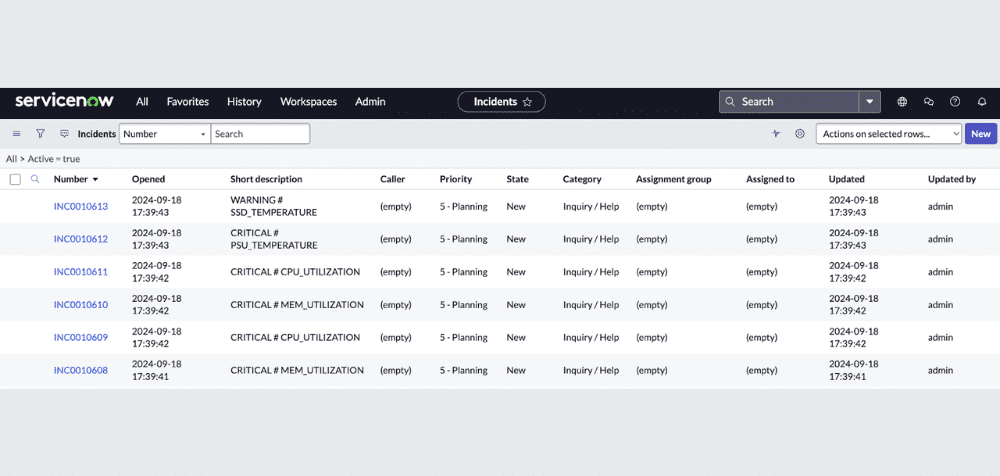
- AI for Networks – See how AI-driven assistants like Network Copilot™ are redefining network operations with automation and real-time insights.
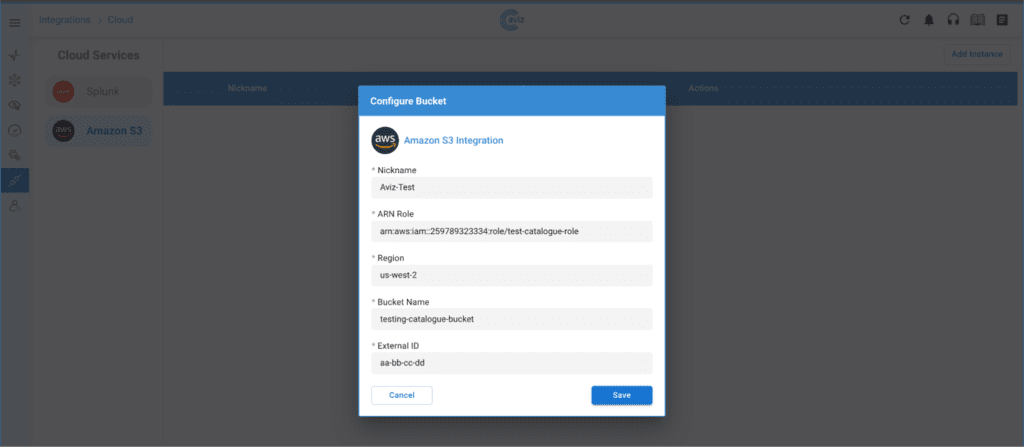
- Aviz ONES + NVIDIA Spectrum™-X – Explore the next-gen AI networking solution built for Ethernet-based GPU cloud infrastructures.

Why This Matters
AI is no longer just an application—it’s the backbone of modern enterprise infrastructure. But here’s the challenge: AI workloads are hungry for bandwidth, require extreme precision, and demand real-time optimization. Aviz Networks and NVIDIA are solving this with cutting-edge AI networking innovations.
Don’t just read about AI in networking—experience it. Watch our exclusive demo and join the panel discussion at NVIDIA GTC!