

In February, we introduced the ONE Data Lake as part of our ONES 2.1 release, highlighting its integration capabilities with Splunk and AWS. In this blog post, we’ll delve into how the Data Lake integrates specifically with the S3 bucket of AWS.
A data lake functions as a centralized repository designed to store vast amounts of structured, semi-structured, and unstructured data on a large scale. These repositories are typically constructed using scalable, distributed, cloud-based storage systems such as Amazon S3, Azure Data Lake Storage, or Google Cloud Storage. A key advantage of a data lake is its ability to manage large volumes of data from various sources, providing a unified storage solution that facilitates data exploration, analytics, and informed decision-making.
Aviz ONE-Data Lake acts as a platform that enables the migration of on-premises network data to cloud storage. It includes metrics that capture operational data across the network’s control plane, data plane, system, platform, and traffic. As an enhanced version of the Aviz Open Networking Enterprise Suite (ONES), ONE-Data Lake stores the metrics previously used in ONES in the cloud.
Why AWS S3?
- 1. Effective Integration and Ecosystem:
- 2. Durability and Reliability:
- 3. Security:
- 4. Scalability:
- 5. Cost Effectiveness:
- 7. Disaster recovery and Backup:
- 6. Data Management and Analytics:
Integrating S3 with ONES:
- 1. Mapping S3 instance with the ONES server
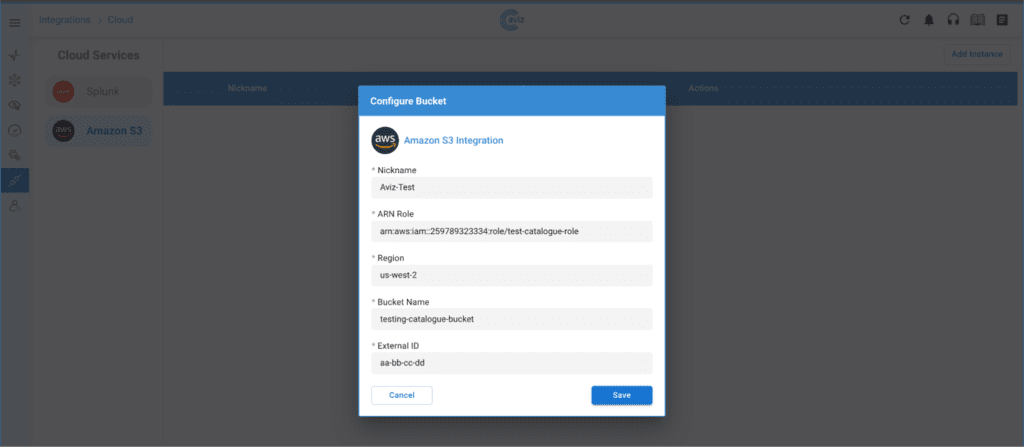
- Configure S3 Instances: Set up the S3 instances on the ONES cloud page to start pushing metrics to the designated cloud endpoint.
- Provide Necessary Details: The following information is required for the integration:
- ARN Role: The unique identifier for the role that grants permissions to access specific AWS resources, including S3 buckets
- Region: The AWS region where your S3 bucket is located
- Bucket Name: The globally unique name of your S3 bucket
- External ID(Optional): An external ID is an additional security measure used when granting cross-account access to IAM roles.
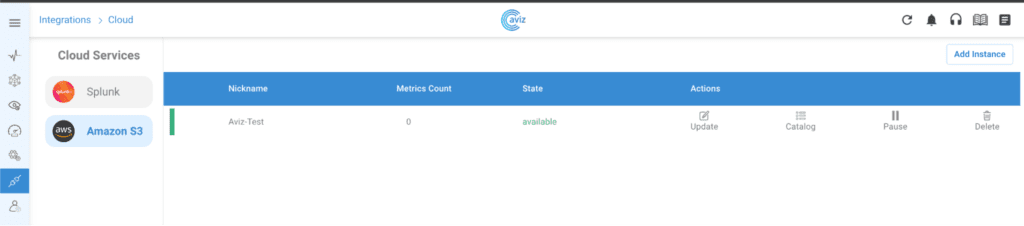
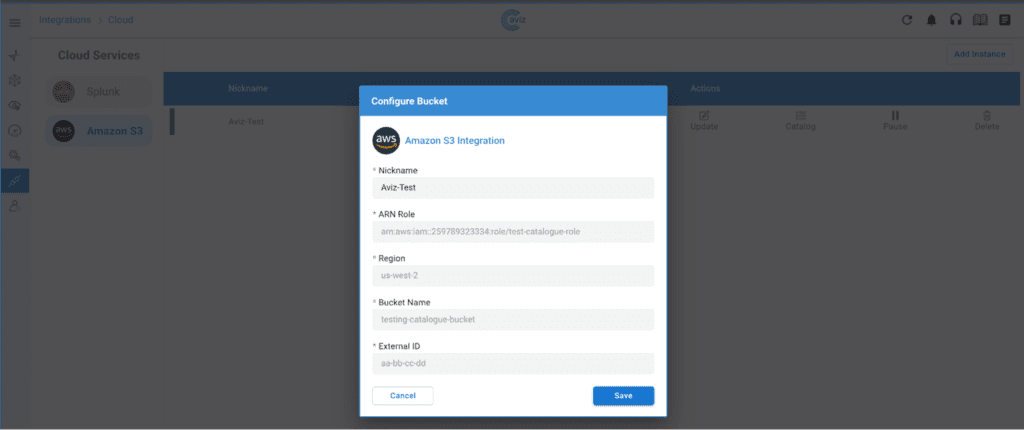
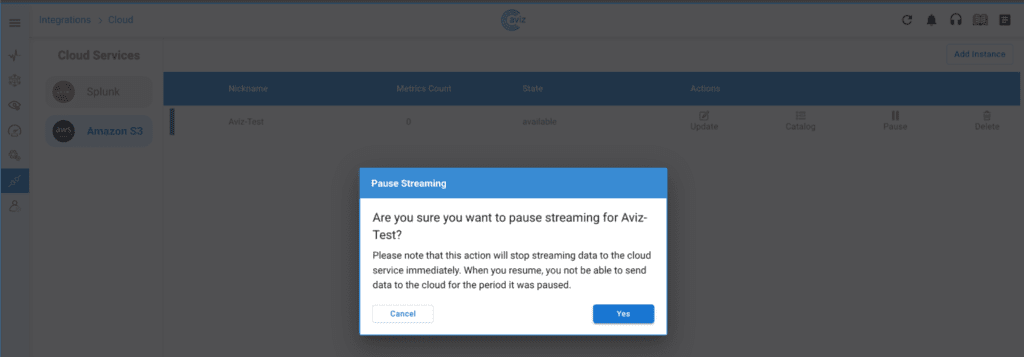
- 2. Managing the created Instance through ONES:
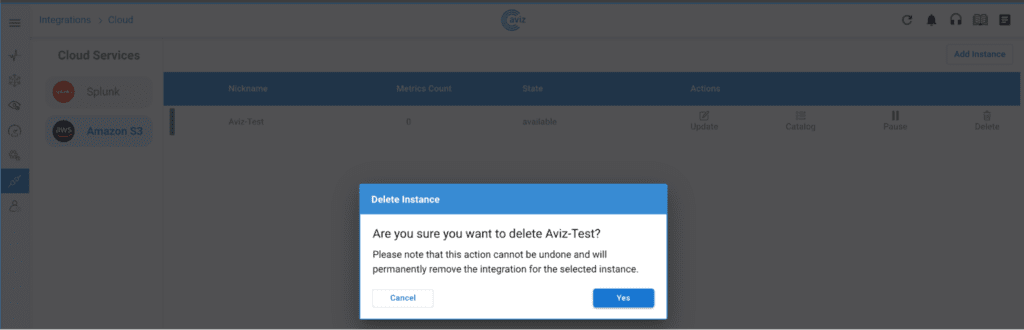
- 3. User defined metric update:
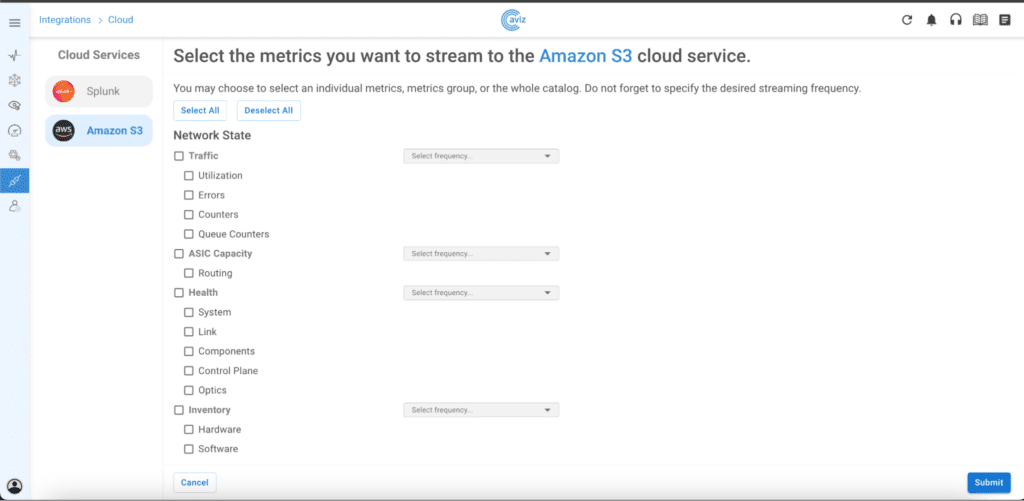
- 4. Multi vendor support
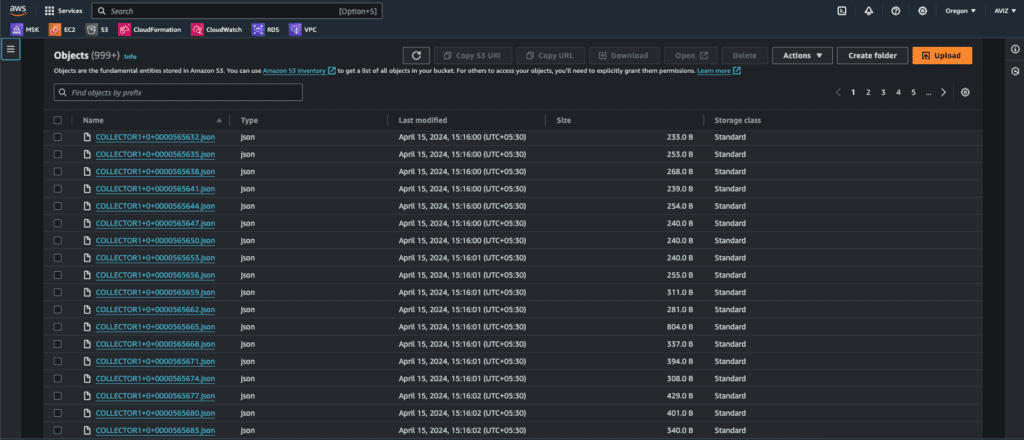
S3 Analytical capabilities:
AWS Athena:
Description: A serverless interactive query service that allows you to run SQL queries directly against data stored in S3.
Use Case: Ad-hoc querying, data exploration, and reporting.
Example: Querying log files, CSVs, JSON, or Parquet files stored in S3 without setting up a database.
AWS Glue:
Description: A managed ETL (Extract, Transform, Load) service that helps prepare and transform data for analytics.
Use Case: Data preparation, cleaning, and transformation.
Example: Cleaning raw data stored in S3 and transforming it into a more structured format for analysis.
AWS SageMaker:
Description: A fully managed service for building, training, and deploying machine learning models.
Use Case: Machine learning and predictive analytics.
Example: Training machine learning models using large datasets stored in S3 and deploying them for inference.
Third-Party Tools:
Description: Numerous third-party tools integrate with S3 to provide additional analytical capabilities.
Use Case: Specialized data analysis, data science, and machine learning.
Example:Using tools like Databricks, Snowflake, or Domo to analyze and visualize data stored in S3.
Custom Applications:
Description: Developing custom applications or scripts that use AWS SDKs to interact with S3.
Use Case: Tailored data processing and analysis.
Example: Writing Python scripts using the Boto3 library to process data in S3 and generate reports.
Conclusion:
Unlock the ONE-Data Lake experience— schedule a demo on your preferred date, and let us show you how it’s done!
